
 🕒 3 min.
🕒 3 min.RESUMEN:
No, al menos en este experimento Google ha evaluado la página destino de las redirecciones y en los casos en que esta se encontraba bloqueada por robots.txt no ha seguido la redirección.
El objetivo de este experimento es comprobar cómo actúa el crawler de Google cuando se encuentra una redirección que apunta a una URL que está bloqueada por robots.txt mediante una regla de disallow.
¿Decide no seguirla debido a que tiene procesado el robots.txt desde el principio y no quiere gastar recursos? ¿La sigue pero luego no rastrea la página de destino debido al bloqueo?
Hipótesis
Google hará una petición a la URL redirigida pero no rastreará la URL de destino.
Grupo experimental
- 3 enlaces que redirigen por 301 a páginas bloqueadas por robots.txt.
- 3 enlaces que redirigen por 302 a páginas bloqueadas por robots.txt.
Grupo de control
- 3 enlaces que redirigen por 301 a páginas no bloqueadas por robots.txt.
- 3 enlaces que redirigen por 302 a páginas no bloqueadas por robots.txt.
Variable independiente
La URL final está bloqueada por robots.txt.
Variable dependiente
Googlebot sigue la redirección.
Proceso
Se crea una página (que se va a denominar página 0) en este mismo dominio que contiene 12 enlaces que se dividen en dos grupos de 6:
Grupo experimental (A)
6 redirigen a páginas que se han creado y bloqueado por robots.txt numeradas del 1 al 6.
Grupo de control (B)
6 redirigen a páginas que se han creado y no se han bloqueado por robots.txt, también numeradas del 1 al 6.
En cada grupo de 6:
- 3 redirigen mediante código de respuesta 301.
- 3 redirigen mediante código de respuesta 302.
Se envía la página 0 a través de Google Search Console para solicitar su rastreo e indexación:
Para averiguar cuál ha sido el comportamiento de googlebot se descargan los logs de acceso del servidor y se analizan utilizando la herramienta Screaming Frog Log Analyzer.
Resultado
Esta ha sido la actividad que ha mostrado googlebot en un plazo de 30 minutos tras enviar la solicitud por GSC:
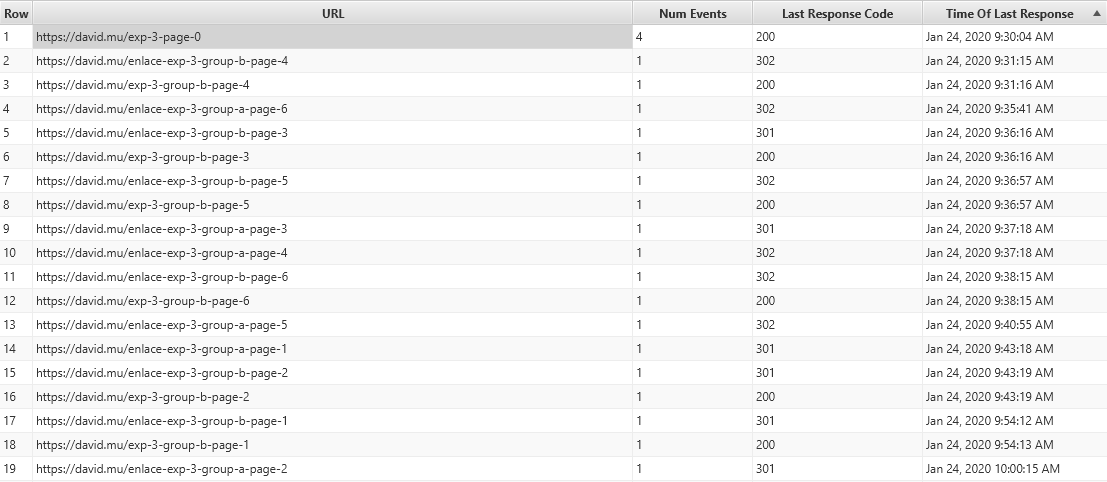
Ordenando las URLs se puede observar que ha hecho peticiones a los 12 enlaces:

Pero solo ha seguido las redirecciones 301 y 302 a las páginas del grupo B,, ya que estas son las únicas URLs de destino que muestran peticiones:

Conclusiones
Cuando googlebot encuentra una respuesta de servidor 301 o 302 al seguir un enlace, parece evaluar la URL de destino y no sigue la redirección si dicha URL se encuentra bloqueada en el archivo robots.txt (que siempre procesa previamente antes de empezar a rastrear una web).