
 🕒 3 min.
🕒 3 min.TL;DR:
No, at least in this experiment Google has evaluated the final page of the redirects and when it was blocked in robots.txt it has not followed the redirect.
The goal of this experiment is to verify how the Google crawler reacts when it finds a redirection that points to a URL blocked with robots.txt through a disallow rule.
Does it decide not to follow it because it processes the robots.txt from the beginning and does not want to waste resources? Does it follow it but then do not crawl the landing page due to the robots blocking?
Hypothesis
Google will request the redirected URL but will not crawl the final URL.
Experimental group
- 3 links redirected with 301 to pages blocked in robots.txt.
- 3 links redirected with 302 to pages blocked in robots.txt.
Control group
- 3 links redirected with 301 to pages that are not blocked in robots.txt.
- 3 links redirected with 302 to pages that are not blocked in robots.txt.
Independent variable
The final URL is blocked in robots.txt.
Dependent variable
Googlebot follows the redirect.
Process
A page is created (it will be named page 0) in this domain that contains 12 links divided into two groups of 6:
Experimental group (A)
6 redirect to pages that have been created and blocked in robots.txt, numbered from 1 to 6.
Control group (B)
6 redirect to pages that have been created but are not blocked in robots.txt, also numbered from 1 to 6.
In each group of 6:
- 3 redirect with a 301 response code.
- 3 redirect with a 302 response code.
A request is sent via GSC for Google to crawl and index page 0:
In order to find out how googlebot is behaving, the server access logs are downloaded and analyzed using the tool Screaming Frog Log Analyzer.
Results
This has been the googlebot activity for 30 minutes after sending the request in GSC:
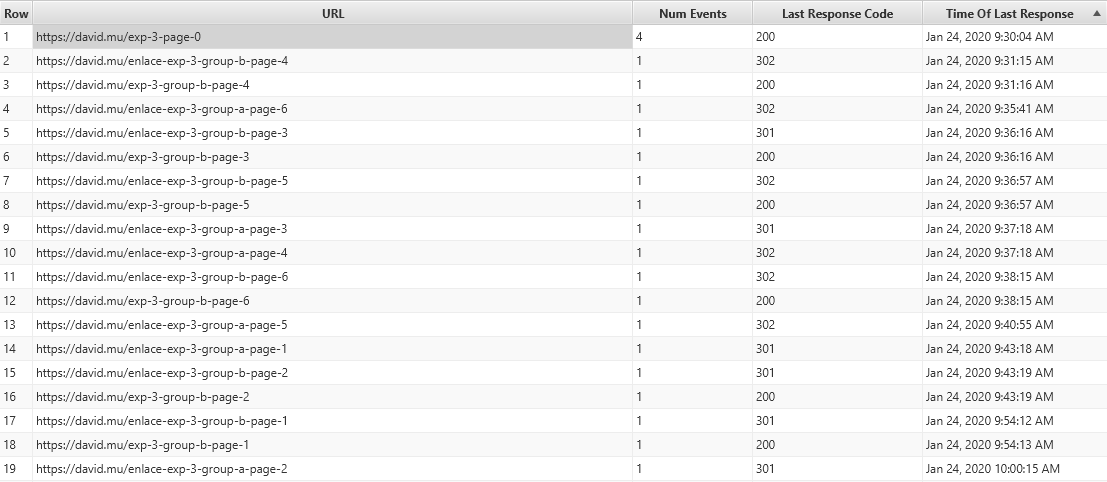
Sorting the URLs, it can be observed that googlebot has requested the 12 links:
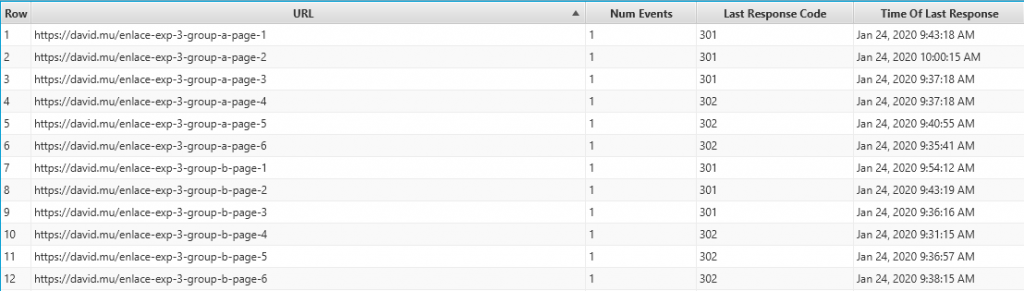
But it has only followed the 301 and 302 redirects to those pages of group B, because those are the only destination URLs showing requests.

Conclusions
When googlebot finds a 301 or 302 server response after following a link, it seems to evaluate the destination URL and won’t follow the redirect if that URL is blocked in the robots.txt file (which always process before starting to crawl a website).